
Python网络爬虫与信息提取
第一章:网络爬虫-规则
第一单元:Requests库入门
The Website is the API…
Win平台: “以管理员身份运行”cmd,执行 pip install requests
import requests
r = requests.get(“https://www.baidu.com")
print(r.status_code)
r.text
Requests库的get()方法
requests库提供7个方法,但是都是以request.request()方法为基础的,所以我们可以认为只有一种方法。
r = requests.get()包含两个对象:Response和Request
1 | requests.get(url, params=None, **kwargs) |
| url | 拟获取页面的url链接 |
|---|---|
| params | url中的额外参数,字典或字节流格式,可选 |
| **kwargs | 12个控制访问的参数 |
Response对象的属性
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
理解两种编码方式
- r.encoding:如果header中不存在charset,则认为编码为ISO‐8859‐1
r.text根据r.encoding显示网页内容 - r.apparent_encoding:根据https网页内容分析出的编码方式
可以看作是r.encoding的备选
爬取网页的通用代码框架
| 异常 | 说明 |
|---|---|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
r.raise_for_status() ———–如果不是200,产生异常requests.HTTPError
r.raise_for_status()在方法内部判断r.status_code是否等于200,不需要
增加额外的if语句,该语句便于利用try‐except进行异常处理
1 | try: |
HTTP协议及Requests库方法
HTTP协议
HTTP,Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层(在TCP之上)协议
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:[:port][path]
URL:是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
host: 合法的Internet主机域名或IP地址
port: 端口号,缺省端口为80
path: 请求资源的路径
HTTP协议对资源的操作
| 方法 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得该资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的数据 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |

Requests库的方法
POST方法:向URL POST一个字典,自动编码为form(表单);向URL POST一个字符串
自动编码为data
requests.request(method, url, **kwargs)的参数
params : 字典或字节序列,作为参数增加到url中
1 | >>> kv = {'key1': 'value1'} |
data : 字典、字节序列或文件对象,作为Request的内容
1 | >>> kv = {'key1': 'value1', 'key2': 'value2'} |
json : JSON格式的数据,作为Request的内容
1 | >>> kv = {'key1': 'value1'} |
headers : 字典,HTTP定制头
1 | >>> hd = {'user‐agent': 'Chrome/10'} |
cookies : 字典或CookieJar,Request中的cookie
auth: 元组,支持HTTP认证功能
files : 字典类型,传输文件
1 | >>> fs = {'file': open('data.xls', 'rb')} |
timeout : 设定超时时间,秒为单位
1 | >>> r = requests.request('GET', 'http://www.baidu.com', timeout=10) |
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
1 | >>> pxs = { 'http': 'http://user:pass@10.10.10.1:1234' |
allow_redirects : True/False,默认为True,重定向开关
stream : True/False,默认为True,获取内容立即下载开关
verify : True/False,默认为True,认证SSL证书开关
cert: 本地SSL证书路径
二单元:网络爬虫”盗亦有道“-Robots协议
网络爬虫的限制
• 来源审查:判断User‐Agent进行限制
检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问
• 发布公告:Robots协议
告知所有爬虫网站的爬取策略,要求爬虫遵守
Robots协议:在网站根目录下的robots.txt文件
- http://www.baidu.com/robots.txt
- http://news.sina.com.cn/robots.txt
- http://www.qq.com/robots.txt
- http://news.qq.com/robots.txt
- http://www.moe.edu.cn/robots.txt (无robots协议)
Robots协议基本语法
1 | 注释,*代表所有,/代表根目录 |
第三单元:Requests库爬取实例
1.京东实例爬取
1 | import requests |
2.亚马逊网站爬取
1 | import requests |
3.百度/360网站关键词提交
1 | import requests |
4.网络图片的爬取
1 | import requests |
5.ip地址归属地的自动查询
1 | import requests |
思考:网站上有些人机交互的按钮都是由链接的形式提交,建议挖掘一下网站的API。
第二章:网络爬虫-提取
单元四:Beautiful库入门
Beautiful Soup库的安装
- Win平台: “以管理员身份运行”cmd
执行pip install beautifulsoup4
Beautiful Soup库的安装小测
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
手工获取demo.html源代码,浏览器右键“查看源代码”:
或者,用Requests库获取demo.html源代码:
1
2
3
4
5
6
7import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
print(r.text)
soup = BeautifulSoup('demo', 'html.parser')
#soup = BeautifulSoup('<p>data</p>', 'html.parser')
print(soup.prettify())
Beautiful Soup库的基本元素
理解:Beautiful Soup库是解析、遍历、维护“标签树”的功能库
1 | <p>..</p> : 标签 Tag |
也就是说:BeautifulSoup对应一个HTML/XML文档的全部内容
1 | soup = BeautifulSoup('<html>data</html>', 'html.parser') |
Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,’html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,’lxml’) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,’xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,’html5lib’) | pip install html5lib |
BeautifulSoup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字, … 的名字是’p’,格式: |
| Attributes | 标签的属性,字典形式组织,格式: |
| NavigableString | 标签内非属性字符串,<>…</>中字符串,格式: |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
任何存在于HTML语法中的标签都可以用soup.
访问获得
当HTML文档中存在多个相同对应内容时,soup. 返回第一个 每个
都有自己的名字,通过 .name获取,字符串类型 一个
可以有0或多个属性,字典类型 Comment是一种特殊类型,可能在文本分析时会在特殊地方用到
基于bs4库的HTML内容遍历方法
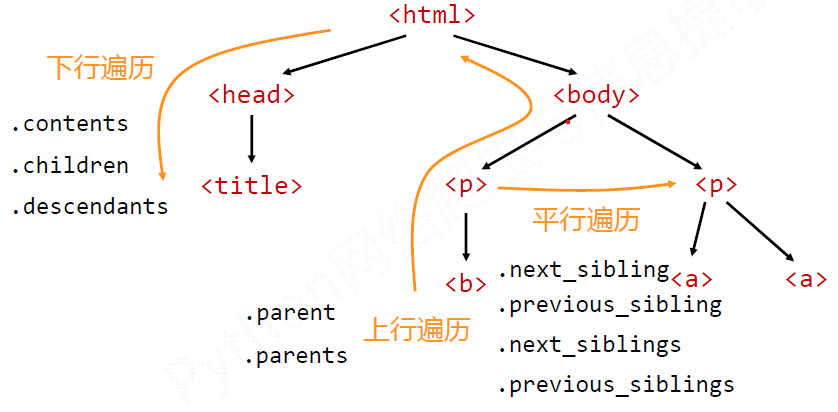
下行遍历-对选定的节点
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
1 | for child in soup.body.children: |
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循坏遍历先辈节点 |
注意:遍历所有先辈节点,包括soup本身,所以要区别判断
平行遍历:必须发生在同一个父节点下的各节点间
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
基于bs4库的HTML格式输出-能否让HTML内容更加“友好”的显示?
bs4库的prettify()方法——-易于阅读
- .prettify()为HTML文本<>及其内容增加更加’\n’
- .prettify()可用于标签,方法:
.prettify()
bs4库的编码
- bs4库将任何HTML输入都变成utf‐8编码
- Python 3.x默认支持编码是utf‐8,解析无障碍
单元五
单元六
python编写图形化界面
Python图形界面开发的几种方案
Tkinter
- 基于Tk的Python库,这是Python官方采用的标准库,优点是作为Python标准库、稳定、发布程序较小,缺点是控件相对较少。
PySide2、PyQt5
- 基于Qt 的Python库,优点是控件比较丰富、跨平台体验好、文档完善、用户多。
缺点是 库比较大,发布出来的程序比较大。
QT界面开发教程
通过一个例子来学习,打开你的python编辑器
先给出一段代码
1 | import sys |
QApplication 提供了整个图形界面程序的底层管理功能,比如:
- 初始化、程序入口参数的处理,用户事件(对界面的点击、输入、拖拽)分发给各个对应的控件,等等…
- 既然QApplication要做如此重要的初始化操作,所以,我们必须在任何界面控件对象创建前,先创建它。
QMainWindow、QPlainTextEdit、QPushButton 是3个控件类,分别对应界面的主窗口、文本框、按钮
他们都是控件基类对象QWidget的子类。
要在界面上
创建一个控件,就需要在程序代码中创建这个控件对应类的一个实例对象。在 Qt 系统中,控件(widget)是
层层嵌套的,除了最顶层的控件,其他的控件都有父控件。QPlainTextEdit、QPushButton 实例化时,都有一个参数window,如下
1
2QPlainTextEdit(window)
QPushButton('统计', window)就是指定它的父控件对象 是 window 对应的QMainWindow 主窗口。
而 实例化 QMainWindow 主窗口时,却没有指定 父控件, 因为它就是最上层的控件了。
控件对象的 move 方法决定了这个控件显示的位置。
控件对象的 resize 方法决定了这个控件显示的大小。
界面动作处理 (signal 和 slot)
在 Qt 系统中, 当界面上一个控件被操作时,比如 被点击、被输入文本、被鼠标拖拽等, 就会发出 信号 ,英文叫 signal 。就是表明一个事件(比如被点击、被输入文本)发生了。
我们可以预先在代码中指定 处理这个 signal 的函数,这个处理 signal 的函数 叫做 slot 。
比如,我们可以像下面这样定义一个函数
1
2def handleCalc():
print('统计按钮被点击了')然后, 指定 如果 发生了button 按钮被点击 的事情,需要让
handleCalc来处理,像这样1
button.clicked.connect(handleCalc)
用QT的术语来解释上面这行代码,就是:把 button 被 点击(clicked) 的信号(signal), 连接(connect)到了 handleCalc 这样的一个 slot上
大白话就是:让 handleCalc 来 处理 button 被 点击的操作
1 | import sys |
代码封装–python如何自定义类
1 | from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QPlainTextEdit,QMessageBox |
界面设计师 Qt Designer
安装之后,在qtappliation下运行designer.exe又出现了问题,好多文章都无法解决
This application failed to start because no Qt platform plugin could be init
解决办法:主要是designer.exe同级的platform文件夹中的两个文件少一个,将上一级的platform文件夹中的两个文件复制并且替换即可
