
Person Re-identification in the 3D Space + 第一次跑代码
论文展示
论文代码
论文阅读
背景
人的再识别通常被认为是在不重叠的摄像机中定位人的图像检索问题
In this paper, we argue that the key to learning an effective and scalable person representation is to consider both the human appearance and 3D geometry structure. With the prior knowledge of 3D human geometry information, we could learn a depth-aware model, thus making the representation robust to real-world scenarios. As shown in Figure 1, we map the visible surface to the human mesh,
and make the person free from the 2D space. Without the need to worry about the part matching from two different viewpoints, the 3D data structure eases the matching difficulty in nature. The model could concentrate on learning the identity-related features, and dealing with the other variants, such as illumination.在本文中,我们认为学习有效和可扩展的人的表示的关键是同时考虑人的外观和三维几何结构。有了三维人体几何信息的先验知识,我们可以学习一个深度感知模型,从而使表示鲁棒的真实场景。如图1所示,我们将可见表面映射到人体网格,并将人从2D空间中解放出来。三维数据结构在本质上减轻了零件匹配的难度,无需从两种不同的角度进行零件匹配。该模型可以集中学习与身份相关的特征,并处理其他变量,如光照。
To fully take advantage of the 3D structure and 2D appearance, we propose a novel Omni-scale
Graph Network for person re-id in the 3D space, called OG-Net. The model is based on graph
neural network (GNN) to communicate between the discrete cloud points of arbitrary locations. In
particular, following the spirit of the conventional convolutional neural network (CNN), we adopt
the KNN-Graph [30] to capture the information from neighbor points.To leverage multi-scale information in 3D data, we propose the Omni-scale module to aggregate the feature from multiple 3D receptive fields. Given the 3D point cloud and the corresponding color information, OG-Net predicts the person identity and outputs the robust human representation for subsequent matching.为了充分利用3D结构和2D外观的优势,我们提出了一种新颖的Omni-scale Graph网络,用于3D空间中的人员身份识别,称为OG-Net。 该模型基于图神经网络(GNN)在任意位置的离散云点之间进行通信。 特别是,按照传统的卷积神经网络(CNN)的精神,我们采用KNN-Graph [30]来捕获来自邻居点的信息。为了利用3D数据中的多尺度信息,我们提出了Omni-scale模块 汇总来自多个3D接收字段的要素。 给定3D点云和相应的颜色信息,OG-Net可以预测人的身份并输出健壮的人像表示以进行后续匹配。
那么什么是KNN-Graph?
- knn即k邻近分类算法,包括距离KNN和概率KNN。
相关工作:点云分割—-https://www.cnblogs.com/li-yao7758258/p/8182846.html
The point cloud is a flexible geometric representation of 3D data
structure.One of the earliest works, i.e., PointNet [15], proposes to
leverage the multi-layer perceptron (MLP) networks and max-pooling layer to fuse the information from multiple points.点云是3D数据结构的灵活几何表示。最早的作品之一,即PointNet [15],提出利用多层感知器(MLP)网络和最大池化层来融合来自多个点的信息。
- pointnet:介绍可以看https://zhuanlan.zhihu.com/p/77019339
讨论班想到的一个推断问题
论文主体结构
OG-net由模块omni-scale Moudle,所以先要明白omni-scale Moudle的结构
Omni-scale Module
理解Dynamic Graph Convolution
该文章是最新出的一篇针对点云数据分类、分割的网路,它是受PointNet以及PointNet++的启发所进行的修改,PointNet只是独立处理每个点,同过最大池化后的全局特征来进行网络输出,但忽视了点之间的局部特征。
动态体现在—–KNN图每次都要重新计算
对距离点x_{i}与离它最近的K个点的特征(由公式)进行一个通道级的对称聚合
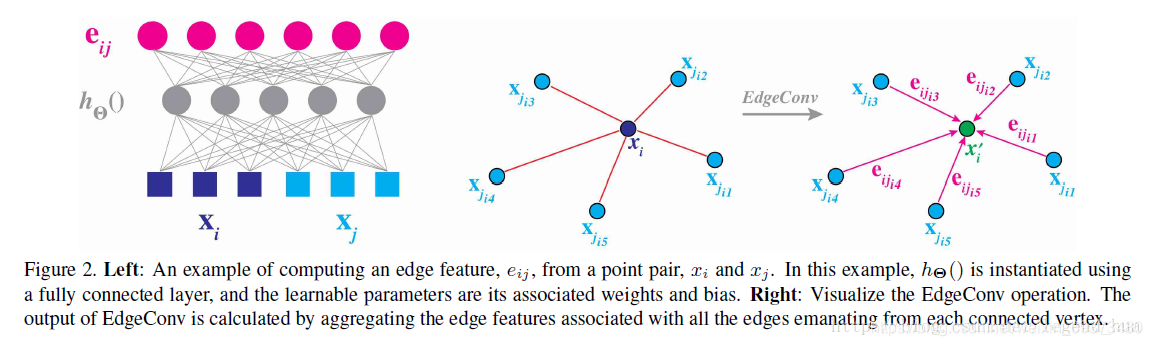
动态图卷积提取局部还是全局的特征取决于h(x_{i},x_{j})
具体细节
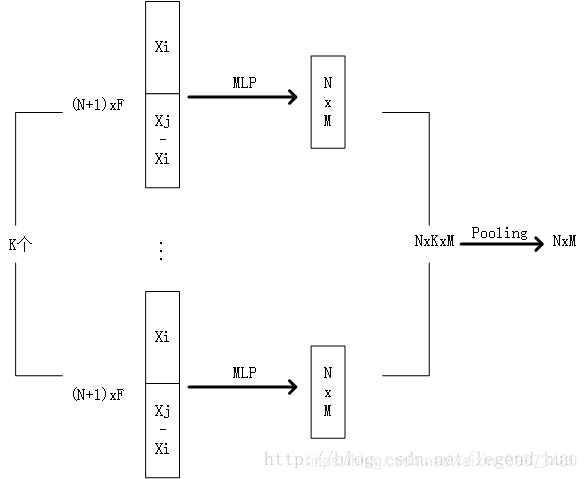
https://blog.csdn.net/weixin_39373480/article/details/88724518
omni-scale Moudle输入输出
input:RGB/KNN/location
output:new feature/location
下采样
location—–>fps算法下采样—–>selected location
根据selected location选择selected feature
我们部署三个分组率不同的分支r ={8,16,32},这三个分支不共享权重。
这样,我们可以像传统的二维神经网络[26]一样,捕获具有不同感受野的信息。每个分支由一个分组层、两个线性层、两个批处理归一化(BN)层、一个压榨激励(SE)块[7]和一个组max池化层来聚合本地信息。具体来说,grouping-r层是对每个点的r个最近点进行采样和复制,然后是线性层、批归一化和SE块。在总结三个分支之前,我们引入SE-block[7]作为一个自适应门函数来重新缩放每个分支的权重x0= x×sigmod(h(x))。
SE-block
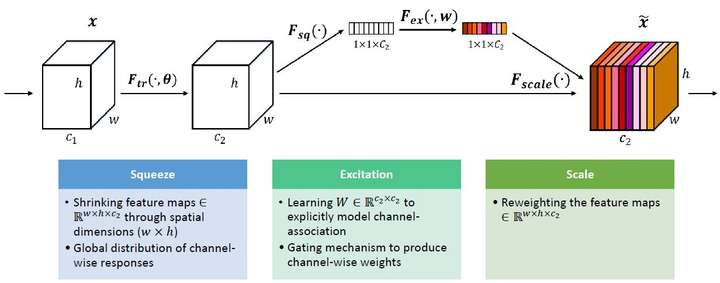
SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。
$$F_{tr} : X \rightarrow U, X\in R^{W’\times H’\times C’},U\in R^{W \times H\times C}$$
那么这个Ftr的公式就是下面的公式1(卷积操作,vc表示第c个卷积核,xs表示第s个输入)
$$ u_{c}=v_{c}\cdot X=\sum_{s=1}^{C’}v_{c}^{s} \cdot x^{s}$$
Ftr得到的U就是Figure1中的左边第二个三维矩阵,也叫tensor,或者叫C个大小为H*W的feature map。而uc表示U中第c个二维矩阵,下标c表示channel。
接下来就是Squeeze操作,公式非常简单,就是一个global average pooling:
$$ z_{c}= F_{sq}(u_{c})=\frac{1}{W \times H}\sum_{i=1}^{W}\sum_{j=1}^{H}u_{c}(i,j) $$
因此公式2就将HWC的输入转换成11C的输出,对应Figure1中的Fsq操作。为什么会有这一步呢?这一步的结果相当于表明该层C个feature map的数值分布情况,或者叫全局信息。
再接下来就是Excitation操作,如公式3。直接看最后一个等号,前面squeeze得到的结果是z,这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量。又因为z的维度是11C,所以W1z的结果就是11C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C*C/r,因此输出的维度就是11C;最后再经过sigmoid函数,得到s。
$$ s = F_{ex}(z,W) = \sigma(g(z,W)) = \sigma(W_{2}\delta(W_{1}z))$$
也就是说最后得到的这个s的维度是11C,C表示channel数目。这个s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
在得到s之后,就可以对原来的tensor U操作了,就是进行channel-wise multiplication。uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。对应Figure1中的Fscale。
$$ \widetilde{X_{c}} = F_{scale}(u_{c},s_{c}) = s_{c} \cdot u_{c}$$
SENet(Squeeze-and-Excitation Networks)算法笔记https://blog.csdn.net/u014380165/article/details/78006626
最后,我们使用“添加”来计算三个分支的总和而不是连接
你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
omni-scale Moudle总结
To summarize, the key of Omni-scale Module is two cross-point functions. The cross-point function
indicates the function considers the neighbor points, while the pre-point function only considers
the feature of one point itself. One cross-point function is the dynamic graph convolution before
downsampling, which could be simply formulated asPh(xi, xj). It mimics the conventional 2D
CNN to aggregate the local patterns according to the position. The other is the max group pooling
layer in each branch, which could be simply formulated as maxh(xi). It maximizes neighbor features
in each group as the new point feature
综上所述,全尺度模块的关键是两个交叉点函数。交叉点函数表示函数考虑相邻点,而前置点函数只考虑一个点本身的特征。一个交叉点函数是降采样前的动态图卷积,可以简单地表示为asPh(xi, xj)。模拟传统的二维CNN,根据位置聚合局部模式。另一个是每个分支中的max组池化层,可以简单表示为maxh(xi)。将每组中的近邻特征最大化作为新的点特征
这里用两个全连接层先降维再升维的目的和原理是什么呢?
降维是为了更简单的计算权重部分,而且实验也给出r不同取值对结果的影响;而升维是必须的,这样才能和原来的Uc相乘,得到每一层特征的权重。
OGNet Architecture
OG-Net的结构由四个Omniscale模块组成。与传统CNN一样,我们逐步减少选择点的数量。每减少一个点,外观特征的通道数就增加一倍。经过四个全尺度模块,512-dim外观特征得到96个点。与[30]类似,我们使用max pooling和average pooling对点特征进行聚合,并将两个输出连接起来,得到1024-dim feature。通过添加全连通层和批量归一化层,将特征压缩到512维作为行人表示。
在进行推理(实际应用)时,我们去掉最后一个线性分类器进行借口分类任务,提取512-dim特征进行图像匹配。
线性分类器
https://scientificrat.com/2018/06/21/%E7%90%86%E8%A7%A3softmax%E5%88%86%E7%B1%BB%E5%99%A8/写的
Training Objective
条件概率是指事件A在事件B发生的条件下发生的概率。
$$ P(A \mid B)= \frac{P(AB)}{P(B)}$$
损失函数$$ L_{id} = \mathbf{E}[-log(p(y_{n} \mid s_{n}))]$$
其中$$p(y_{n} \mid s_{n})$$是sn归属于ground-truth类yn的预测可能性。训练目标要求模型能够根据输入点区分不同的身份。
Experiment
Qualitative Results
Quantitative Results
Further Analysis and Discussions
实际运行代码时遇到的问题
实验要求pytoch 1.4.0版本
配置环境失败(这可能是每次都会遇到的)
1 | pip install -r requirements.txt |
解决方法一:
查出原因是在执行这一语句前需要先创建requirements.txt 文件,所以必须先执行
1
pip freeze > requirements.txt
解决方法二:
直接打开
下载数据集
数据集在Google Drive里。之前,我都是通过浏览器直接下载的,但是经常下载到一半就失败了。查了很多方法,都没有解决,甚至还让别人帮忙保存到百度云……最后,终于找到了成功下载的办法。
下载速度提升10倍以上,大大节省了时间成本
- 安装IDM。下载IDM(IDM官网),默认安装即可。
- 如果第一步安装完,chrome中没有成功安装IDM插件,可按照以下步骤安装。
1)进入官网菜单栏Support下的FAQ中。
2)进入 BROWSER INTEGRATION QUESTIONS
4)点击下载安装。
服务器下载数据集
因为文件太大,不能进行移动,demo形式是onedrive和Google drive。
onedrive -耗时2小时解决
step1:首先打开官方分享界面链接,发现并不是真是下载的地址。点开之后,找个文件点击下载,然后取消,在devtool中输入文件名字,可以找到真实链接
step2:如果直接在服务器里 wget 这个下载链接,100%会403: Forbidden。有经验的老手都知道肯定是没带 Cookie ,但是要怎么带Cookie呢,其实很简单(???)
首先你需要按下F12,打开开发人员工具,然后转到网络选项,之后点击想要下载的文件进行下载,同时观察开发人员工具窗口,找到带有download.aspx/?…. 的那个链接
之后在那个链接上右键,选择 复制-复制为cURL命令(POSIX)
会在剪切板出现类似下面的命令语句
1
curl 'https://gitaccuacnz2-my.sharepoint.com/personal/mail_finderacg_com/_layouts/15/download.aspx?UniqueId=cb44677f%2Dc4af%2D44ad%2D88d4%2Dceb07d9625da' -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'Accept-Language: zh-HK,zh-TW;q=0.5' --compressed -H 'Connection: keep-alive' -H 'Referer: https://gitaccuacnz2-my.sharepoint.com/personal/mail_finderacg_com/_layouts/15/onedrive.aspx?.......' -H 'Cookie: CCSInfo=NS8yOS8yMDIwIDEwOjE1OjE0IEFNC/.....; FeatureOverrides_enableFeatures=; FeatureOverrides_disableFeatures=' -H 'Upgrade-Insecure-Requests: 1' -H 'Sec-Fetch-Dest: iframe' -H 'Sec-Fetch-Mode: navigate' -H 'Sec-Fetch-Site: same-origin'
之后粘贴到Linux的命令行里,最后在后面补加一句
--output file.extension,其中file.extension是想要保存的文件名。最终执行的命令就是类似这样的:1
curl 'https://gitaccuacnz2-my.sharepoint.com/personal/mail_finderacg_com/_layouts/15/download.aspx?UniqueId=cb44677f%2Dc4af%2D44ad%2D88d4%2Dceb07d9625da' -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'Accept-Language: zh-HK,zh-TW;q=0.5' --compressed -H 'Connection: keep-alive' -H 'Referer: https://gitaccuacnz2-my.sharepoint.com/personal/mail_finderacg_com/_layouts/15/onedrive.aspx?.......' -H 'Cookie: CCSInfo=NS8yOS8yMDIwIDEwOjE1OjE0IEFNC/.....; FeatureOverrides_enableFeatures=; FeatureOverrides_disableFeatures=' -H 'Upgrade-Insecure-Requests: 1' -H 'Sec-Fetch-Dest: iframe' -H 'Sec-Fetch-Mode: navigate' -H 'Sec-Fetch-Site: same-origin' --output file.extension
同时这个方法也适合文件夹下载,只不过前缀是
xxxxx-mediap.svc.ms,其中xxxxx是地区代号,不同的下载链接所指向的地区不同,具体看情况,这里就不再赘述。如果使用Chrome下载,需要选择 复制cURL(Bash) 然后把里面的换行和\ 都处理掉,要不然会不行,但是我没成功过,按理讲应该是能成功的,算了,Firefox能用就行了,又不是天天下载。


